
How Long Should You Analyze with a Chess Engine? Introducing Confidence Score
If you’ve ever analyzed a position with an engine, you’ve probably experienced this moment of confusion.
The engine shows a stable, equal evaluation for several minutes, making it seem like it has fully understood the position. But then it suddenly finds a deeper idea, and the evaluation jumps significantly, leaving you wondering what would have happened if you had stopped the engine just a few seconds earlier. Naturally, you keep facing the same question every time: how long is enough, and when can you actually trust the engine’s suggestions?
The reality is that engines like Stockfish work by exploring millions of possible continuations, going deeper and deeper with each second. Early on, it only sees a shallow version of the position. As it digs further, it begins to uncover hidden tactics, defensive resources, and long-term ideas that were invisible at first.
That’s why evaluations change. Not because the engine is unreliable, but because it’s gradually becoming more informed.
The real challenge is that engines give you an answer — a number and a line — but they don’t tell you how much you should trust it. A +1.5 evaluation might be rock solid, or it might collapse completely with a bit more search. From the outside, those two situations look identical.
This gap becomes even more noticeable when you compare different setups. On a powerful cloud server, the engine might reach a stable conclusion quickly. On a weaker device, the same position can remain unstable for much longer. The evaluation is the same type of output — but the work behind it is completely different.
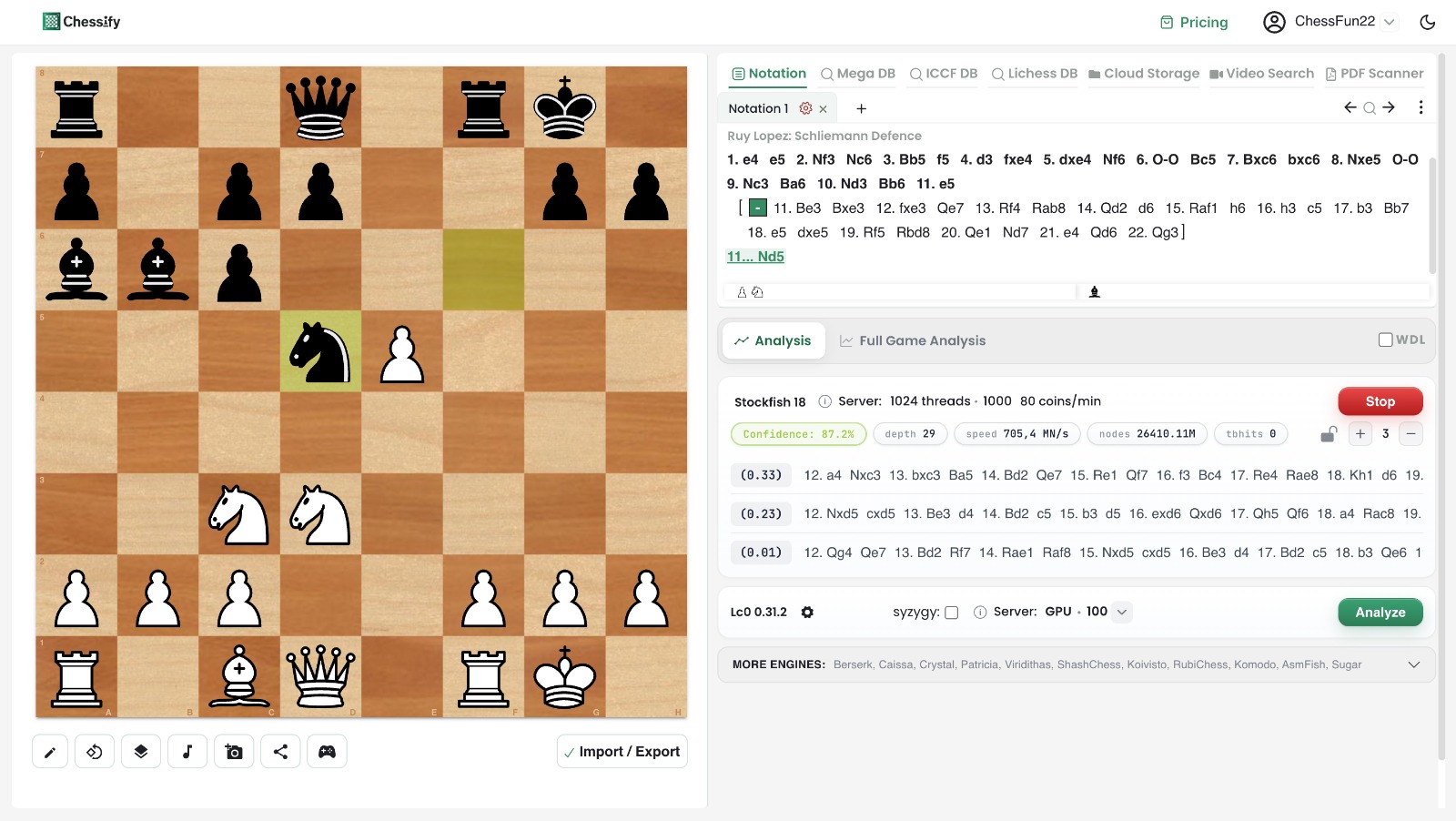
This is exactly the problem we set out to solve with Chessify. Today, we’re introducing a new engine metric called Confidence.
What does “Confidence” actually measure?
In Chessify, Confidence is a single number that answers:
How much can I trust this evaluation right now?
In other words, it measures whether the engine has done enough work, and whether its understanding is stable enough, for the result to be meaningful.
There are two key ideas behind it.
The first is search effort. The more positions the engine analyzes, and the deeper it goes, the more complete its picture becomes. A shallow search can miss critical ideas entirely, while a deeper one is far more likely to uncover them. This is also why stronger servers in Chessify tend to reach reliable conclusions faster — they can simply explore more of the position in the same amount of time.
But effort alone isn’t enough. An engine can search millions of positions and still fail to fully stabilize on a single line if the position is complicated. That’s where stability comes in.
If the evaluation is still unsettled or the best move keeps changing, it’s a clear sign that the engine is still figuring things out. On the other hand, if the evaluation remains consistent and the main line stays the same as the search deepens, it usually means the engine has “settled” on its understanding.
To estimate both search effort and stability, we combine several signals from the engine — some obvious, and some that are usually hidden from users.
Here’s what goes into it:
- Nodes (search effort)
The number of positions the engine has analyzed. More nodes generally mean a more thorough search and a lower chance of missing something important.
- Depth (search maturity)
How deeply the engine has calculated into the position. Higher depth usually means better understanding, especially in simpler positions.
- Stability of the evaluation and main line
If the score and the best move keep changing over consecutive iterations, the engine is still figuring things out. If they stay consistent, the position is likely settled.
- Competing moves (when MultiPV is enabled)
If multiple moves are nearly equal, the engine is less certain. If one move clearly stands out, it’s much less likely to change later.
- Search consistency (internal engine behavior)
This includes signals like whether the engine had to repeatedly re-search positions or adjust its expectations. These are subtle indicators that something might still be unstable under the surface.
- Hash usage (search memory pressure)
The engine uses a memory structure (called a hash table) to store and reuse analyzed positions. If this becomes overloaded, the engine may start losing useful information and become less consistent. Although this is one of the less important factors, it can sometimes signal instability before it becomes visible in the evaluation itself.
Thanks to the combination of these factors, we arrive at a Confidence score that helps you decide whether to trust the engine’s analysis or continue analyzing.

Why position complexity matters
Confidence behaves very differently depending on the position.
In simple positions, confidence rises quickly. There are fewer meaningful choices, fewer hidden resources, and the engine reaches a stable conclusion without needing enormous search depth. Even on a modest setup, the evaluation becomes reliable fairly fast.
In complex positions, the situation is very different. There may be long forcing lines, subtle defensive ideas, or multiple competing plans. The engine needs much more time — or more computational power — to explore everything properly. Until it does, even a convincing-looking evaluation can still be fragile.
This is why relying on the raw number alone can be misleading. The evaluation tells you what the engine currently thinks, but not how much weight you should give to that opinion.
Confidence fills that gap.
What Confidence tells you in practice
In practice, Confidence changes how you approach analysis.
When confidence is low, it’s a signal to keep the engine running — there may still be important ideas hidden beneath the surface. When confidence is moderate, you can start forming conclusions, but with caution. And when confidence is high, you can rely much more on what you’re seeing, knowing that both the search and the evaluation have reached a stable point.
The key takeaway is simple. Engines are incredibly powerful, but they don’t arrive at the truth instantly. They build it step by step through search. Confidence helps you see where you are in that process — not just what the engine thinks, but how much that opinion is worth.
To give this new feature a try, simply turn on analysis on Chessify.
Final notes
Note that Confidence is currently available only for engines that support WDL. Engines like Patricia, RubiChess, and AsmFish will not display a Confidence score.
In addition, some engines (such as Koivisto and Viridithas) provide only a single principal variation. In those cases, certain signals — like line stability across multiple variations or variation gap — are not included in the calculation.
Confidence is a new feature, and we appreciate any feedback or suggestions. You can reach us at info@chessify.me.



